Melody transcription
Description
get to know the notes of a sung or hummed melody
SampleSumo's Melody Transcription (MeloTranscript) library, is a technology package for offline monophonic melody transcription.
Basically, what this technology does is the following: you give it a sound recording with a vocal melody, and MeloTranscript gives you back a sequence of notes, with a start time, end time, average pitch, and amplitude for each detected note in the sound recording.
In short: it gives you the notes you just sang or hummed.
Note that It was mainly built for use with vocal melodies (singing, humming, singing with dadada, fafafa, etc...). With other monophonic material (flute, clarinet, trumpet, …), your miles may vary.
This technology is based on an research carried out at Ghent University. More information in the references section below.
Licensing
MeloTranscript is available as a C/C++ library with documentation, development guide and example code. We currently support Windows, macOS and iOS (other platforms available upon request).
If integration through the use of an executable (for use on your server) is preferred, we can also provide a console application that can be run in batch mode for scripting through Python, etc...
Contact us for more details, pricing info or an evaluation license to get started.
Evaluation
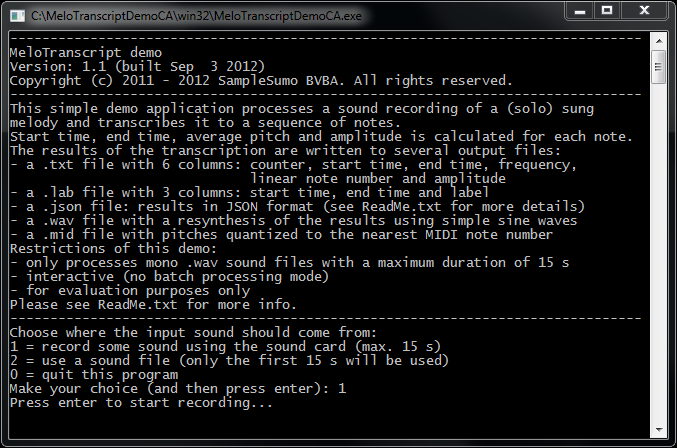
If you would like to evaluate the technology yourself, you can DOWNLOAD our simple technical demo application for Windows and macOS.
Examples
| Humming male 1 | Humming male 1 - transcript resynth. with sines |
| Humming male 2 | Humming male 2 - transcript resynth. with sines |
| Little girl singing | Little girl singing - transcript resynth. with sines |
Applications and use cases
- sing a tune and see the notes you just sang
- sing a tune and hear what you sang, but played back by another instrument
- use as a front end for a melody search engine
- use a sequence of notes as a password or as a key in a game
- music education: imitate a melody as good as possible, sing a specific note, …
References
- "An Auditory Model Based Transcriber of Vocal Queries", T. De Mulder, J.P. Martens, M. Lesaffre, M. Leman, B. De Baets, H. De Meyer, in: Proceedings of the International Conference on Music Information Retrieval, Baltimore, Maryland, USA and Library of Congress, Washington, DC, USA, October 26-30, 2003 (ISMIR 2003)
- "Recent improvements of an auditory model based front-end for the transcription of vocal queries", T. De Mulder, J.P. Martens, M. Lesaffre, M. Leman, B. De Baets, H. De Meyer, Proceedings of the IEEE International Conference on Acoustics, Speech and Signal Processing, (ICASSP 2004), Montreal, Quebec, Canada, May 17--21, 2004, Vol.~IV, 2004, 257--260. (ISBN: 0-7803-8484-9, ISSN: 1520-6149)